사실 6월에 여행일정 + 약속이 너무 많았어서 앉아서 강의를 듣는 것도 쉽지 않았다.
하지만 정보처리기사 실기 합격 소식을 확인하고 다시 의욕이 불타올랐다.
그래 일 다니면서 정처기도 붙었는데 코테도 준비할 수 있겠다!! 라는 마음가짐으로 자리에 앉았다.
30번대에 진입했으니 그래도 작심삼일은 넘겼다. 😂
3주차 공부 기록

저번에 이어서 22번부터 차근차근 문제를 확인하며 내가 메모하고 싶은 문제들만 정리해보았다.

==========================================================================================
문제 26번.
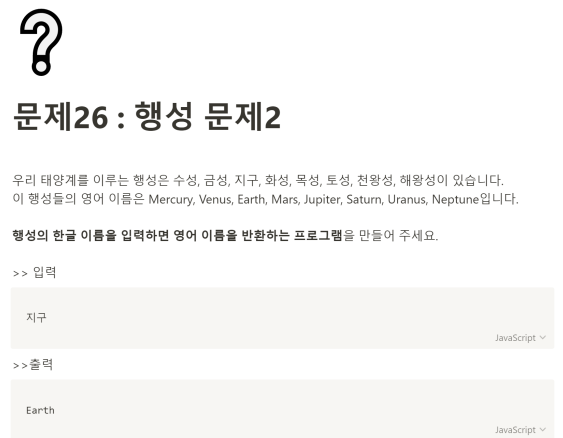
나는 요새 업무에서 딕셔너리를 사용을 많이 하다보니 그냥 딕셔너리만 생각이 났는데,
강의를 통해 생각보다 다양한 방법이 있다는 것을 깨달았다.
**********************************
1. 기본적인 방법 (Dictionary 직접 생성)
행성 = {
'수성' : 'Mercury',
'금성' : 'Venus',
'지구' : 'Earth',
'화성' : 'Mars',
'목성' : 'Jupiter',
'토성' : 'Saturn',
'천왕성' : 'Uranus',
'해왕성' : 'Neptune',
}
name = input()
행성[name]
1-1. Value값을 불러낼 때 .get() 메소드 사용 (Key Error 방지 가능)
## 그냥 행성[name] 으로 불러낼 경우, input 값이 key에 없으면 key error 발생
## get메소드를 사용하면 key가 없으면 출력할 메세지를 설정할 수 있음
행성.get(name, '값 없음')
**********************************
2. zip() 메소드로 2개의 리스트를 튜플 형태로 엮기
# Zip() 함수는 각 데이터들을 병렬처리할 수 있음
행성한글 = ['수성', '금성', '지구', '화성', '목성', '토성', '천왕성', '해왕성']
행성영어 = ['Mercury', 'Venus', 'Earth', 'Mars', 'Jupiter', 'Saturn', 'Uranus', 'Neptune']
# pack (튜플 형태로 병렬 처리)
zip(행성한글, 행성영어)
# dictionary 형태로
행성이름 = dict(zip(행성한글, 행성영어))
※ zip 사용할 때 두 인자의 length가 다르면 짧은 것을 기준으로 잘라버리기 때문에,
데이터가 손실될 위험이 있음
======================================================================================
# pack한 애들을 unpacking도 가능
행성한글, 행성영어 = zip(*행성이름)
**********************************
3. 직접 엮지 않고, 인덱스를 활용하기 (index 메소드)
# 1. index() 메소드
행성한글 = ['수성', '금성', '지구', '화성', '목성', '토성', '천왕성', '해왕성']
행성영어 = ['Mercury', 'Venus', 'Earth', 'Mars', 'Jupiter', 'Saturn', 'Uranus', 'Neptune']
name = input()
# 행성한글에서 name이 몇번째인지 확인하고, 행성영어의 같은 인덱스 번호에 해당하는 값 출력
행성영어[행성한글.index(name)]
==========================================================================================
문제 29번.
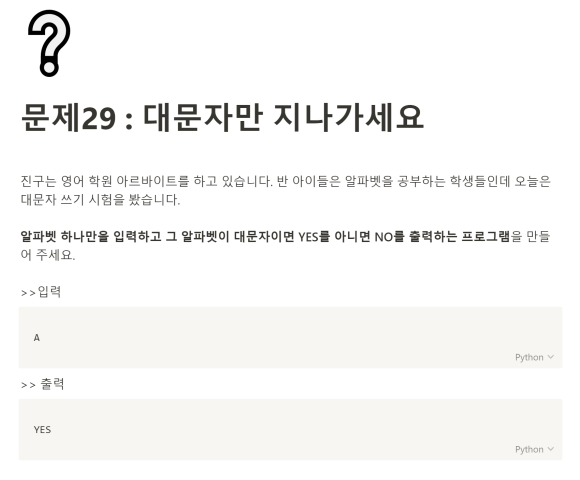
당연히 isupper() 로 true/false 값을 뽑아낼 줄 알았는데, 아스키코드를 사용하는 방법이 있었다!
1. isupper() 함수 사용
data = input()
# 대문자일 땐 YES
if data.isupper():
print('YES')
else:
print('NO')
**********************************
2. ord(), chr() 사용
data = input()
# chr() : 숫자 -> 문자로
# ord() : 문자 -> 숫자로
# 정상종료 초기화
정상종료 = True
# data 문자를 하나씩 돌면서 대문자에 해당하는지 확인,
# 소문자가 하나라도 있으면 정상종료 = False로 변경하고 중단
for i in data:
if ord(i) >= 65 and ord(i) <= 90:
continue
else:
정상종료 = False
break
else:
print('YES')
if not 정상종료:
print('NO')
==========================================================================================
문제 30번.
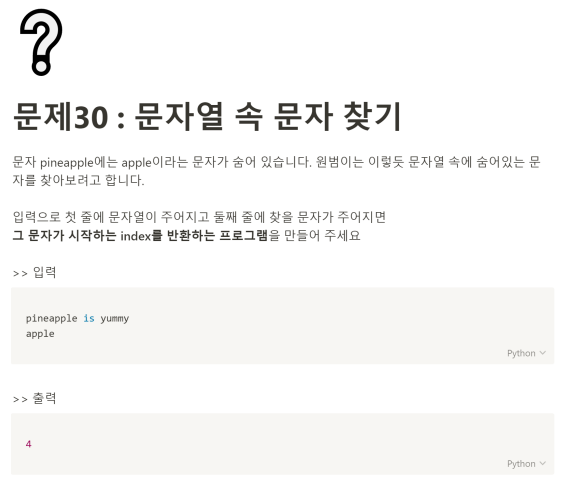
1. 문자열에서 index와 find 함수의 차이점
# 1. index() 함수 - ValueError: substring not found 가 발생할 수 있다.
data = input()
word = input()
if word in data:
print(data.index(word))
# 2. find() 함수 : 값이 없어도 -1 출력
if word in data:
print(data.find(word))
(31~37번) 추가 공부 기록
그 동안 너무 진도가 느렸기 때문에 스퍼트를 위해서 좀 더 추가로 공부하려고 한다.

==========================================================================================
문제 32번.
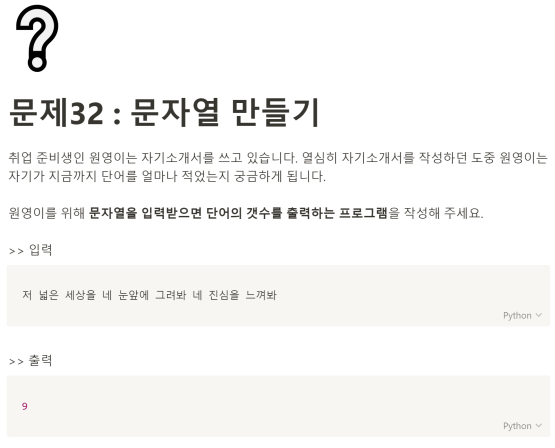
띄어쓰기를 기준으로 문자열을 나누어서 리스트로 만든 뒤, 공백만 제거하고 length를 구하면 된다.
data = '안녕하세요. 저는 제주대학교 컴퓨터공학전공 혜림입니다.'
# 공백을 기준으로 split
splitdata = data.split(' ')
# 띄어쓰기 사이에 있는 공백들까지 다 포함돼서 나옴
print(len(splitdata)) # 17
splitdata # ['안녕하세요.', '', '', '', '', '', '', '', '', '', '', '', '저는', '제주대학교', '컴퓨터공학전공', '혜림입니다.']
# remove는 맨 앞의 하나만 지워주기 때문에 모든 공백을 지우려면,
for문 돌려서 공백 개수만큼 반복해주어야 한다.
for i in range(splitdata.count('')):
splitdata.remove('')
print(splitdata)
# ['안녕하세요.', '저는', '제주대학교', '컴퓨터공학전공', '혜림입니다.']
==========================================================================================
문제 34번.
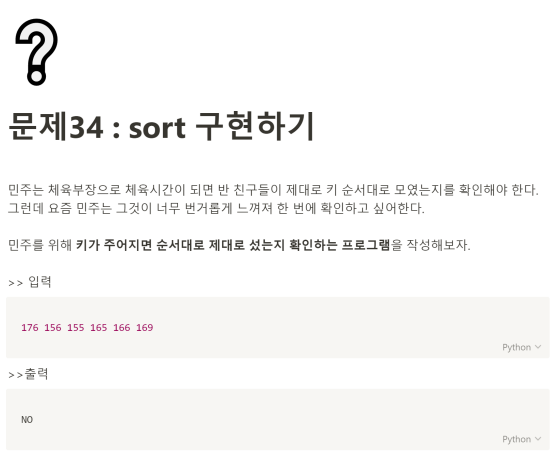
1. sort() 와 sorted()의 차이점
# 1. sort() :
(1) 사용형태 : 리스트.sort() -> "리스트의 메소드"
(2) 원본 리스트를 아예 변경해버림, "반환값 (X)"
print(data.sort())
# None : 반환값이 없어서
print(data)
# [155, 156, 165, 166, 169, 176]
# 2. sorted()
(1) 사용형태 : sorted(리스트) -> "내장 함수"
(2) 원본 리스트랑 별개의 정렬된 리스트를 "반환"
data = [176, 156, 155, 165, 166, 169]
print(sorted(data))
# [155, 156, 165, 166, 169, 176]
# 원본 리스트랑 별개로 반환했으므로 원본은 변화 X
print(data)
# [176, 156, 155, 165, 166, 169]
==========================================================================================
문제 37번.

하나의 문자열로 입력받은 것을 split으로 나눠주고, list안에 최대개수인 문자를 찾아내야 한다.
**********************************
1. count()와 max() 함수 사용
(1) max(iterable, key = 함수, default) : 기본적으로 iterable만 넣어서 사용하고, key와 default는 선택인자다.
max 함수는 데이터분석하면서 기본으로 알아야되는 집계함수여서 사용을 많이 해봤는데..
key라는 게 있는지는 전혀 몰랐었다.
정확한 기준으로 max를 구하도록 돕는 역할이다.
* KEY
"key"
a = [(0, 70), (1, 0), (2, 30), (3, 20)]
# key 없이
max(a)
>>> (3, 20) # 첫번째 인자를 기준으로
=========================================================
# key를 사용한다면? 2번째 인자를 기준으로
max(a, key=lambda x : x[1])
>>> (0, 70)
default도 마찬가지로 필수는 아니지만,
파라미터로 들어간 iterable이 null 일 경우 ValueError가 발생하는데 이를 방지하기 위한 기능이다.
* DEFAULT
"default"
# 사용방법
a=[]
max(a, default = 4)
>>> 4
* Dictionary를 max로 사용할 때 예시
1) max(딕셔너리) : key값을 기준으로 대소 비교
2) max(딕셔너리.values()) : value 값을 기준으로 대소 비교 후, value값 출력
3) max(딕셔너리, key=딕셔너리.get ) : value값으로 대소 비교 후, key값 출력
**********************************
(2) 문제 풀이
# 원범 원범 혜원 혜원 유진 유진 유진 유진 혜원 혜원 혜원 혜원 혜원
# 일단 문자열 리스트로 나누기
data = input().split()
# 중복을 제외한 집합 하나 구하기
data_set = set(data)
# data_set을 key로 가지는 dictionary 생성
data_dict = {}
for key in data_set:
# 각 key가 data에 몇번 나오는지 count 해서 key-value 값으로 넣어주기
data_dict[key] = data.count(key)
# format을 지정해서 print
print(f'{max(data_dict, key=data_dict.get)}(이)가 총 {max(data_dict.values())}표로 반장이 되었습니다.')
# 혜원(이)가 총 4표로 반장이 되었습니다.
==========================================================================================
문제 38번.
이 문제를 풀면서 몰랐던 사실 1가지를 발견하게 됐다.
바로 map 함수인데,
map 함수로 객체를 하나 받아놓으면 1번 사용 후에는 메모리에서 지워지기 때문에 꼭 list로 변경해서 저장해두어야 한다는 점이었다.
강의를 한번 보고 내가 이해한대로 혼자 코드를 짜고 실행했더니 count = 0으로 출력이 되는 것이었다.
원인을 chatGPT가 설명해주었는데..
"파이썬의 map 객체는 이터레이터(iterator)입니다."
"이터레이터는 한 번만 순회할 수 있는 객체로, 데이터를 한 번 소비하고 나면 다시 사용할 수 없습니다.
예를 들어, map(int, input().split())로 생성된 map 객체는 한 번 사용하면 데이터를 모두 소비하여 빈 상태가 됩니다.
이런 이유로 map 객체를 여러 번 사용해야 할 경우, 이를 리스트로 변환하여 메모리에 저장해야 합니다."
내 코드의 문제점을 다시 돌아보면
# 점수 전체 입력받기
data = map(int, input().split())
# [int(i) for i in data] : 리스트 컴프리헨션 (i에 반복적으로 int(i)를 적용할 수 있는 간단한 문법, int(i) for i in data if int(i) % 2 == 0 처럼 조건문도 사용 가능)
# 사탕 줄 사람 초기화
count = 0
# 내림차순 정렬 후에 4위 점수를 break point로 설정
break_point = sorted(list(set(data)), reverse=True)[3]
#
for i in sorted(data, reverse=True):
if break_point == i :
break
else:
print(i)
count += 1
print(sorted(data, reverse=True))
print(count)
==========================================================================
data = map(int, input().split())이 문제였다.
map으로 받아줬기 때문에 break_point에서 한번 sorted를 거치고 난 뒤, data는 빈 상태가 됐다.
밑의 for문의 sorted에 들어가는 data는 빈 값이 돼서 0이 출력됐던 것
그래서 다음과 같이 코드를 수정했다...
data = list(map(int, input().split()))
data를 list로 받아주었더니 메모리에 계속 유지가 됐고, 정상적인 값이 도출됐다.
=========================================================================================
확실히 1주차에 비해서는 난이도 차이가 느껴졌지만,
아직은 수월한 편에 속하는 것 같다.
아마 4주차부터 진도가 현저히 느려지지 않을까 싶다.

<해당 강의 링크>
제주코딩베이스캠프 Code Festival: Python 100제 강의 | 제주코딩베이스캠프 - 인프런
제주코딩베이스캠프 | 이 강좌를 통해 문법을 보다 명확하게 이해하시고, 문제 풀이에 대한 자신감을 얻으시길 바랍니다., [사진] [사진] 안녕하세요! 제주코딩베이스캠프입니다 :) 이번에는
www.inflearn.com
'위니브 엠버서더' 카테고리의 다른 글
| [위니브 엠버서더 3기] 파이썬 코딩테스트 기초 입문 강의 4주차 도전 (0) | 2024.07.30 |
|---|---|
| [위니브 엠버서더 3기] 아주 쉽다 클라우드! AWS Lightsail 자습서! 인프런 클라우드 강의 수강 후기 (13) | 2024.07.30 |
| [위니브 엠버서더 3기] IT 분야를 잘 모르는 비전공자가 들으면 좋은 MBIT 강의 수강 후기 (0) | 2024.07.01 |
| [위니브 엠버서더 3기] 비전공자 파이썬 코딩테스트 기초 강의 추천 (0) | 2024.06.26 |
| [위니브 엠버서더 3기] 제주코딩베이스캠프로 코딩 습관 만들기 챌린지 시작! (0) | 2024.06.24 |